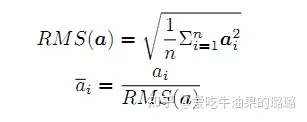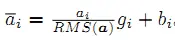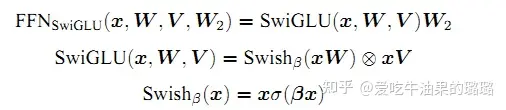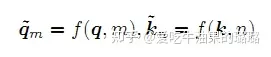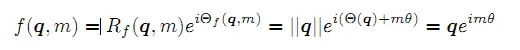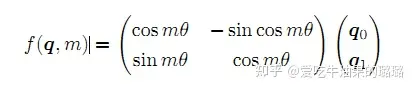模型概览
LLaMA 模型是目前最流行和性能最强大的开源模型之一,基于 LLaMA 所构造的模型生态可以覆盖绝大部分模型使用场景。本节将介绍LLaMA的模型结构及代码实现。
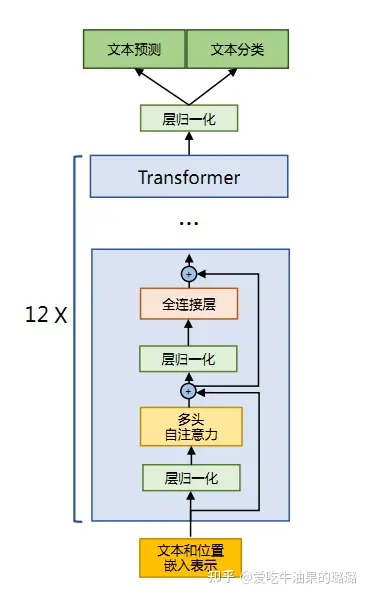
与在之前文章中所介绍的 Transformer架构(爱吃牛油果的璐璐:万字长文全面解析transformer(二更,附代码实现))不同的地方包括采用了前置层归一化(Pre-normalization)并使用RMSNorm归一化函数(Normalizing Function)、激活函数更换为SwiGLU,并使用了旋转位置嵌入(RoP),整体Transformer架构与GPT-2类似,如下图所示。
LLaMA模型结构基本的transformer接下来,将分别介绍RMSNorm归一化函数、SwiGLU激活函数和旋转位置嵌入(RoPE)的具体内容和实现。
RMSNorm 归一化函数
为了使得模型训练过程更加稳定,GPT-2相较于GPT就引入了前置层归一化方法,将第一个层归一化移动到多头自注意力层之前,第二个层归一化也移动到了全连接层之前,同时残差连接的位置也调整到了多头自注意力层与全连接层之后。层归一化中也采用了RMSNorm归一化函数。针对输入向量a,RMSNorm 函数计算公式如下:
此外,RMSNorm 还可以引入可学习的缩放因子 gi 和偏移参数 bi,从而得到:
RMSNorm 在HuggingFace Transformer库中代码实现如下所示:
class LlamaRMSNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-6):
“””
LlamaRMSNorm is equivalent to T5LayerNorm
“””
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps # eps 防止取倒数之后分母为 0
def forward(self, hidden_states):
input_dtype = hidden_states.dtype
variance = hidden_states.to(torch.float32).pow(2).mean(–1,
keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance +
self.variance_epsilon)
# weight 是末尾乘的可训练参数, 即 g_i
return (self.weight * hidden_states).to(input_dtype)
SwiGLU 激活函数
SwiGLU激活函数是Shazeer在文献中提出,并在PaLM等模中进行了广泛应用,并且取得了不错的效果,相较于 ReLU 函数在大部分评测中都有不少提升。在 LLaMA 中全连接层使用带有 SwiGLU激活函数的的计算公式如下:
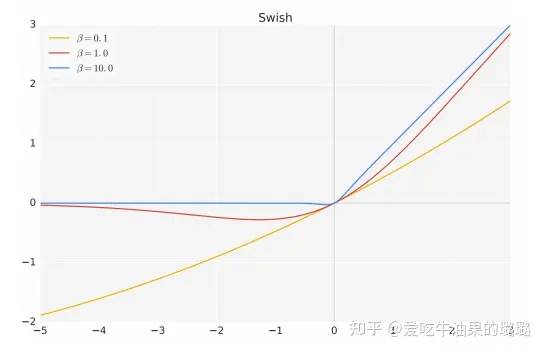
其中,σ(x) 是 Sigmoid 函数。下图给出了 Swish 激活函数在参数 β 不同取值下的形状。可以看到当 β 趋近于 0 时,Swish 函数趋近于线性函数 y = x,当 β 趋近于无穷大时,Swish 函数趋近于 ReLU 函数,β 取值为 1 时,Swish 函数是光滑且非单调。在 HuggingFace 的 Transformer 库中Swish函数使用silu函数代替。
旋转位置嵌入(RoPE)
在位置编码上,使用旋转位置嵌入(Rotary Positional Embeddings,RoPE)代替原有的绝对位置编码。RoPE借助了复数的思想,出发点是通过绝对位置编码的方式实现相对位置编码。其目标是通过下述运算来给q,k 添加绝对位置信息:
经过上述操作后, qm~\tilde{q_{m}} 和 kn~\tilde{k_{n}} 就带有位置m和n 的绝对位置信息。详细的证明和求解过程可以参考文献[52],最终可以得到二维情况下用复数表示的RoPE:
根据复数乘法的几何意义,上述变换实际上是对应向量旋转,所以位置向量称为“旋转式位置编码”。还可以使用矩阵形式表示:
根据内积满足线性叠加的性质,任意偶数维的 RoPE,都可以表示为二维情形的拼接,即:
由于上述矩阵 Rn 具有稀疏性,因此可以使用逐位相乘 ⊗ 操作进一步加快计算速度。RoPE 在HuggingFace Transformer库中代码实现如下所示:
class LlamaRotaryEmbedding(torch.nn.Module):
def __init__(self,
dim,
max_position_embeddings=2048,
base=10000,
device=None):
super().__init__()
inv_freq = 1.0 / (base
**(torch.arange(0, dim, 2).float().to(device) / dim))
self.register_buffer(“inv_freq”, inv_freq)
# Build here to make `torch.jit.trace` work.
self.max_seq_len_cached = max_position_embeddings
t = torch.arange(self.max_seq_len_cached,
device=self.inv_freq.device,
dtype=self.inv_freq.dtype)
freqs = torch.einsum(“i,j->ij”, t, self.inv_freq)
# Different from paper, but it uses a different permutation
# in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
dtype = torch.get_default_dtype()
self.register_buffer(“cos_cached”,
emb.cos()[None, None, :, :].to(dtype),
persistent=False)
self.register_buffer(“sin_cached”,
emb.sin()[None, None, :, :].to(dtype),
persistent=False)
def forward(self, x, seq_len=None):
# x: [bs, num_attention_heads, seq_len, head_size]
# This `if` block is unlikely to be run after we build sin/cos in `__init__`.
# Keep the logic here just in case.
if seq_len > self.max_seq_len_cached:
self.max_seq_len_cached = seq_len
t = torch.arange(self.max_seq_len_cached,
device=x.device,
dtype=self.inv_freq.dtype)
freqs = torch.einsum(“i,j->ij”, t, self.inv_freq)
# Different from paper, but it uses a different permutation
# in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1).to(x.device)
self.register_buffer(“cos_cached”,
emb.cos()[None, None, :, :].to(x.dtype),
persistent=False)
self.register_buffer(“sin_cached”,
emb.sin()[None, None, :, :].to(x.dtype),
persistent=False)
return (
self.cos_cached[:, :, :seq_len, …].to(dtype=x.dtype),
self.sin_cached[:, :, :seq_len, …].to(dtype=x.dtype),
)
def rotate_half(x):
“””Rotates half the hidden dims of the input.”””
x1 = x[…, :x.shape[-1] // 2]
x2 = x[…, x.shape[-1] // 2:]
return torch.cat((-x2, x1), dim=-1)
def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
# The first two dimensions of cos and sin are always 1, so we can `squeeze` them.
cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed